Controllable Text-to-Image Generation with GPT-4
Abstract
本文工作:引入了Control-GPT来指导基于diffusion的文本到图片的pipeline,通过GPT-4生成的纲领性的概述,增强了pipeline跟随指导的能力。
训练时的主要挑战:缺乏对齐文本图像和sketch的数据集。
解决方式:将现有数据集中的实例掩码转换为多边形来模拟使用的草图
Intro
在图片文本生成中更精确的控制依然是艰巨的挑战。当前工作的解决方案:prompt,或者人工的创造图像草图 -> 不高效,难泛化
用户在代码生成(? code generation)中一般有更大的控制权,可以编码来操控物体的多个方面。
GPT-4的在解决复杂编码问题的成功鼓励着本文调查如何利用语言大规模模型(LLM) 来增强可控的文本图片生成模型。
在本工作中,引入Control-GPT,一个简单高效的框架来利用LLMs来基于文本提示生成草图。
实践中,直接使用生成的草图作为分割图并且为给预训练的ControlNet不能得到性能的提升。因为模型可能缺乏对TikZ草图的充分理解,因为预训练的模型在训练过程中没有看到这样的草图。 –> 将现有的实例分割数据集中的实例掩码转换为多边形表示,这种表示类似于GPT-4生成的草图。
Controllable Text-to-Image Generation with GPT-4
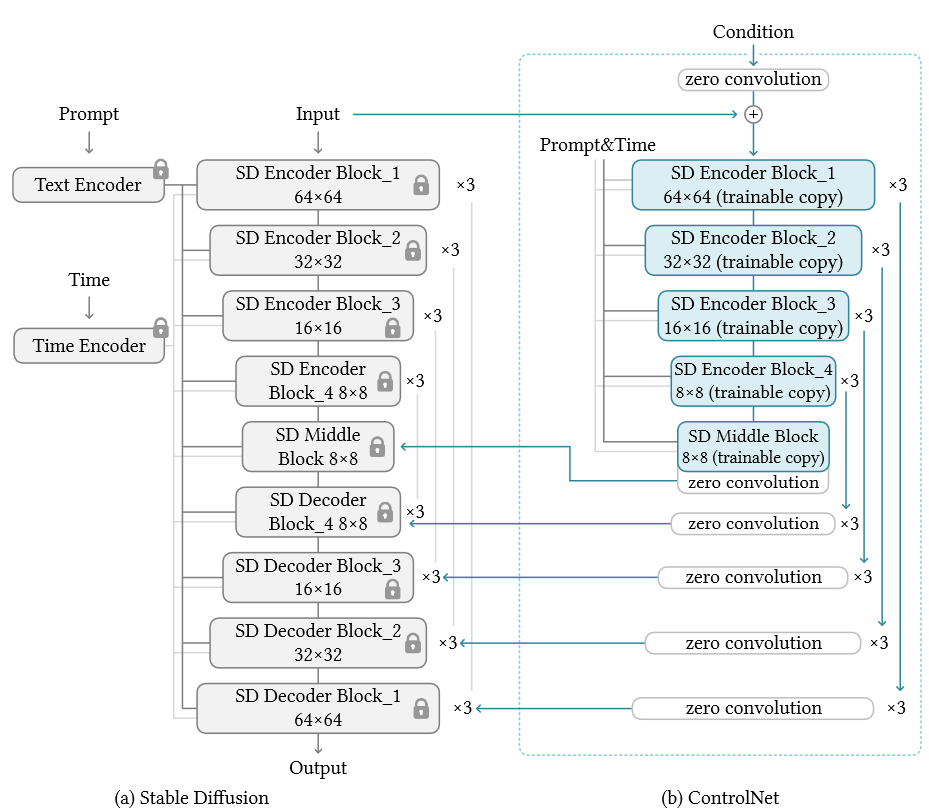
先验知识:ControlNet
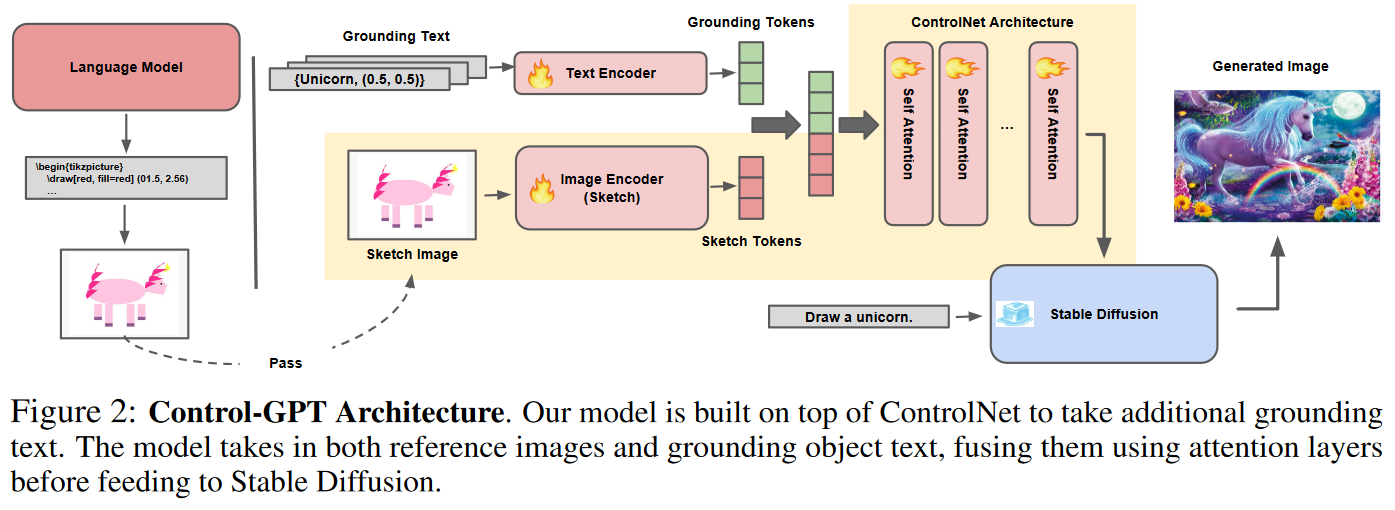
本文框架
训练数据重构
ControlNet不能准确的解释由GPT给出的草图或者提示 –> 需要finetune
困难:很难找到大量的对齐图片-草图对 –> 探索从现有图像数据集中使用注释的方法,并且模仿草图来缓解训练和测试数据之间的差距。
用多边形表现实例掩码然后转换为草图样式的图像可以减小gap
额外的真实对象
作为补充,本文发现添加额外的物体grounding tokens可以进一步消除语义模糊。
在推理过程询问GPT-4获得程序化草图
在画草图的阶段LLMs有多精准?
-> 人工评估 GPT系列比很多开源模型效果显著的好
Experiments
Conclusion
文档信息
- 本文作者:Yimin Zhou
- 本文链接:https://yimchow.github.io/fragment/Controllable%20Text-to-Image%20Generation%20with%20GPT-4/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)