Rethinking Semantic Image Compression Representation with Cross-modality Transfer
Abstract
本文提出了一个可拓展的跨模态压缩范式,SCMC。
融合不同粒度表示的SCMC范式支持不同的应用场景,如高层语义通信和低层图像重建。
解码器能够恢复视觉信息,得益于基于语义、结构和信号层的可伸缩编码。
Intro
语义信息在图像理解中具有内在的关键性,在视觉信息表征中起到重要的作用。
优点:紧凑的表示、对理解友好、与视觉信号紧密相连
可伸缩的压缩通过将视觉信号编码为若干层,已经被证明是一种高效的表示方法。在解码端高层往往依赖于低层的存在。
基于深度学习模型出色的重建能力,紧凑的特征表示和视觉信号压缩可以自然地安如一个统一的可伸缩编码框架。
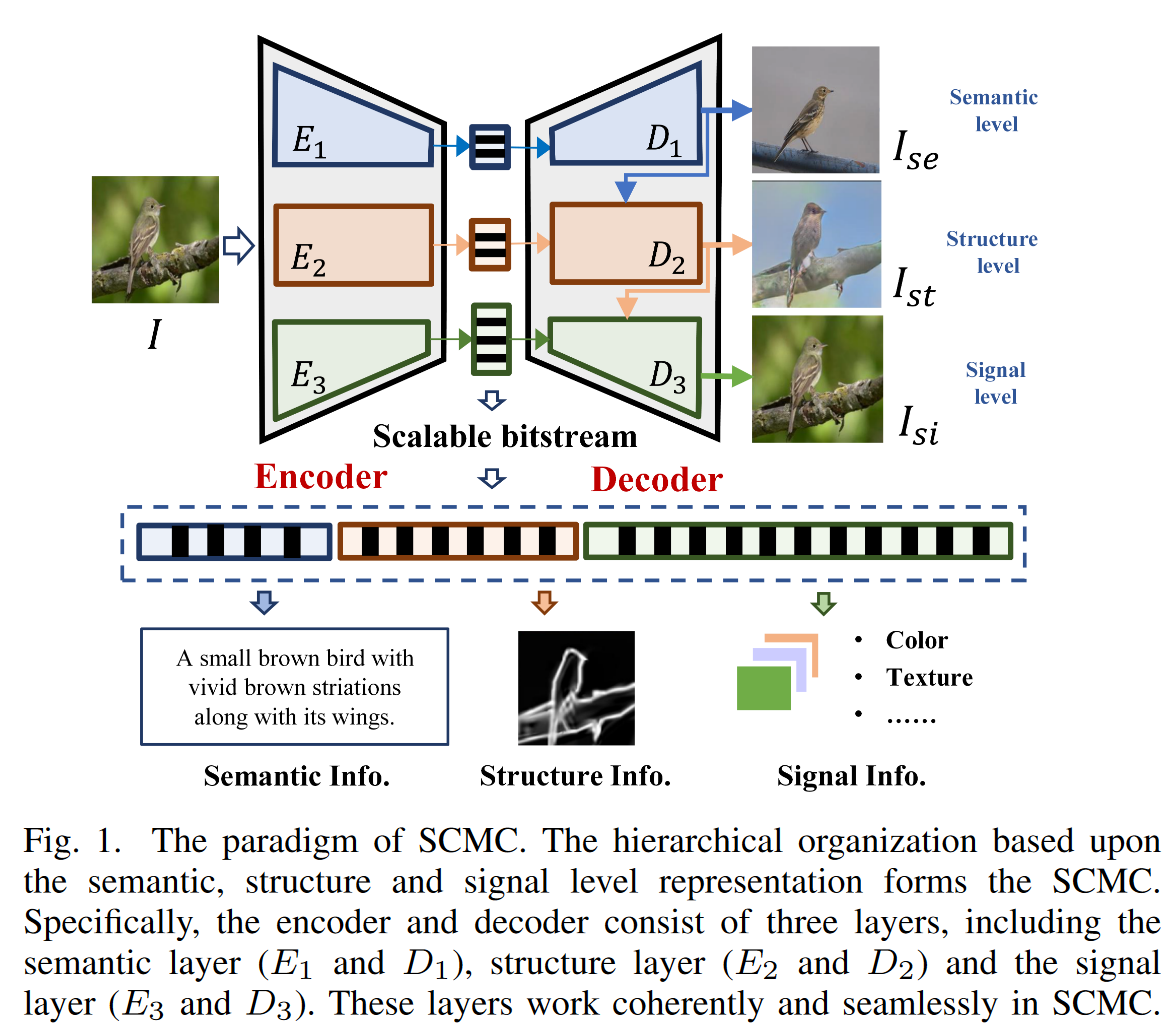
SCMC起到在语义图理解和图像重构之间连接的作用,有三层:语义层,结构层,信号层。
优点:紧凑、灵活、高效。
本文贡献:
- 基于语义提出了新的SCMC框架。
- 在SCMC中设计了三层表征,遵循可伸缩编码框架中的概念组织和连贯的设计思想。
- 制定了三层之间的交互策略,保证较高层的解码能得到较低层的支持。
The Proposed SCMC Framework
拥有一个Encoder,一个Decoder,三层。
语义层 Semantic Layer
基于图像描述的语义信息提取为这一层奠定了基础,可以用极其紧凑的方式表示。基于T2I生成,可以从这一层中生成具有相同语义信息的视觉信号。
这一层的核心在于图-文-图的跨模态转换、压缩和表示。(I2T+T2I)
结构层 Structure Layer
根据Marr理论的启发,几何结构和随机纹理是视觉场景的两个主要组成成分。
在解码端,利用几何结构和语义伦理的组合重建方案来提高表示能力。
这一层包含三个阶段:结构提取并且压缩,结构语义层混合,图片重构
结构提取并压缩
通过RCF(Richer Convolutional Features,一种轮廓检测方案)获得结构图。因为强大的压缩具有锐利和丰富的屏幕内容图像的能力,屏幕内容编码(SCC)工具被使用。
结构-语义层混合
这一阶段包含两个阶段:对齐结构和语义特征,混合对齐的特征。
因为来自第一层的语义生成纹理和来自第二层的结构之间的信息不一致,通过多尺度对齐策略将纹理和结构图转换为特征域来对齐。
对齐后,通过逐元素相加的方式将结构特征融合为自校准卷积后的对齐特征。
图像重构
用LSGANs以端到端的方法训练模型。
为了维持语义一致性和优化视觉质量,引入了新的项:DISTS损失,来进一步增强输入图片和重构图片之间的联系。通过\(L_1\)和\(L_{DISTS}\)的执行,输入图像和生成图像之间的相似性得到了很大的提高,促进了概念表示
\[L_{re}=\lambda_1L_1(I,I_{st})+\lambda_dL_{DISTS}(I,I_{st})\]所以目标函数为
\[G^*=\arg\min_G\max_DL_d(G(I_{se},I_e),D(I))+\lambda_gL_g(G(I_{se},I_e))+L_{re}\]在端到端训练后,结构层结合了结构特征和语义图的纹理信息来推动图像生成。
信号层 Signal Layer
一些信号层的属性(颜色和背景)用来指导原图像信号的重构。
运用结构语义层的信息辅助解码。
本层的损失函数
\[L_{RD}=\lambda L_{mse}+R\]Experiment
数据集:CUB-200-2011(只用鸟类图片会不会太受限了)
评价指标:LPIPS, DISTS,更低的指标表明更好的质量。
比较:JPEG, VVC, Balle的方法(使用CompressAI)
Conclusions
提出了新的SCMC框架,对图像如何通过多种方式进行表示有一些观点,语义,结构,信号。