SMALLCAP: Lightweight Image Captioning Prompted with Retrival Augmentation
Abstract
motivation:最近的image caption工作聚焦于对数据和模型的大小进行缩放,显著的增加了预训练和微调的代价。
工作:提出了SMALLCAP,可以生成一个以输入图像和从数据存储中检索到的相关标题为条件的标题。模型轻量化,快速训练。(cross attention layers)
SMALLCAP可以转换到新的域,而无需额外的微调,可以以免于训练的方式利用大规模的数据,因为数据库的内容是可以随时替换的。
实验:在COCO上训练
Intro
大规模的数据集会使得计算代价变大,对于需要不同的视觉领域和最终用户模型版本时,就特别重要。
之前的工作使用预训练模型(frozen),和之间的映射(hot),用于图片描述任务。问题:两个模型都需要针对每个用例单独训练。
本工作(SMALLCAP),由外部的数据存储的文本中提取出来的描述来提示(prompt),基于输入图片。这种图像描述的形式使一系列理想的性质:轻量化训练、免于训练的域迁移,以免于训练的方式利用大数据。
通过检索,模型可以利用外部数据,最后能够在权重内存储较少的信息。
一旦模型训练好了,我们可以用(1)新的域的描述(2)大量多样的描述来替换数据存储。在情况(1)提供了一种微调的可替代的方法。情况(2)展示了一种泛化预训练的方法。
本模型克服了之前模型的关键限制,需要利用finetuning来适应新的域,从而证明了多模态任务中检索增强的潜力。
Related Work
Image Captioning Models
最近工作:encoder-decoder model, v&l model
Freezing Image Captioning Models
冻结预训练模型中一部分或者全部参数,从而防止灾难性的以往(之前的数据)
Retrieval-Augmented Generation
检索增强语言生成包含了在额外信息的条件上生成,这种额外信息是在外部的数据存储中检索到的。检索增强在其他任务中已经得到了越来越多的帮助,但是在图像描述任务中仍有很大的研究空间。
与之前检索增强任务的不同:
- 采用了一种简单的基于提示的条件化方法。其中检索到的标题作为生成语言模型的提示。
- 首次利用检索增强在无需训练的域转换上,并且在图片描述上泛化。
Prompting Text Generation
Proposed Aprroach
Model
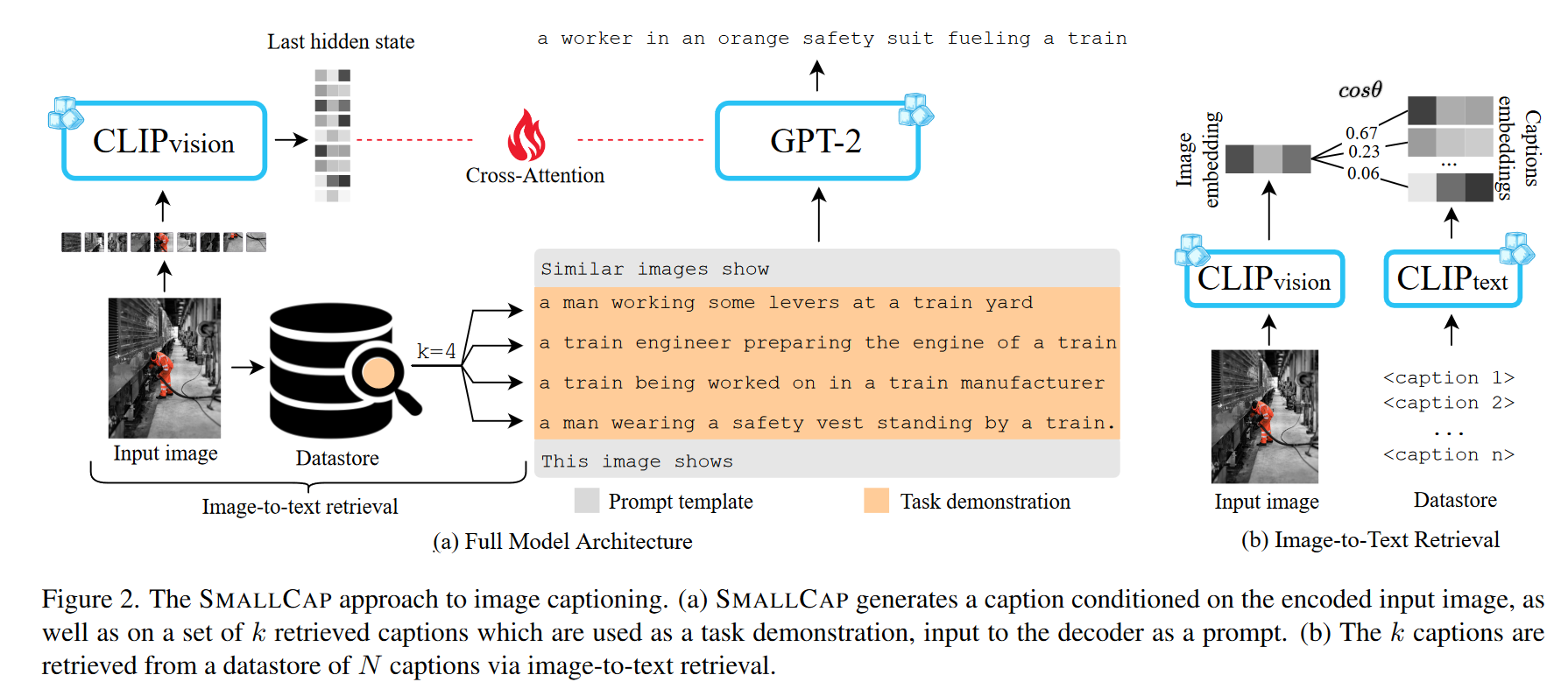
用multi-head cross-attention连接两个模型,只训练这个attention
Prompting with Retrieved Captions
采用image-to-text retrieval,模型可以利用数据存储描述任意类型的文本,文本应该被视作描述图片。这里利用完整的CLIP模型。使用最近邻搜索基于cosine similarity检索出$k$个文本项。
prompt:
Similar image show {caption1} …… {captionk}. This image shows ____
解码器根据此生成描述基于图片特征$V$和任务描述$X$,cross-attention layers的权重训练通过最小化预测$M$个token的交叉熵损失
\[L_\theta=-\sum_{i=1}^M\log P_\theta(y_i|y_{<i},X,V;\theta)\]